Причины ранжирования в ИИ-ответах: перевод исследования
Реклама. ООО «Клик.ру», ИНН:7743771327, ERID: 2VtzqviDgg1
В 2026 году веб-сайту принципиально попасть на лишь в топ выдачи поисковых машин, да и в ответы нейросетей – Алисы Yandex’а и AI Overview в Гугл. Мы перевели исследование Сайруса Шепарда, где он разбирает 23 фактора, которые влияют на цитирование контента в ИИ ответах Гугл.
Методология – как я оценивал эти причины
Все молвят о цитировании контента искусственным умом. Чтоб убедиться, что мы осознаем друг дружку, что мы подразумеваем под цитатами ИИ? Хотя они различаются зависимо от платформы, ИИ цитаты – это кликабельные ссылки на источники, которые системы искусственного ума употребляют для доказательства собственных ответов. К примеру, такие, как показаны ниже.
Хотя никто не оспаривает тот факт, что ответы ИИ уменьшают количество переходов в открытый веб, упоминания могут служить предохранительным клапаном для издателей. Недавнешнее исследование Seer Interactive указывает, что упоминание в ИИ обзорах Гугл приводит к повышению органических кликов на показ на 120% и росту платных кликов на 41% по сопоставлению с ситуацией, когда ваш бренд не упоминается.
Кажется, каждую недельку мы лицезреем новое убедительное исследование ИИ цитат, новейшую теорию либо даже дискуссию о том, что вправду работает.
Но мы отмечаем, что большая часть рекламщиков не вводят эти стратегии в свою работу или поэтому, что не убеждены в их значимости, или из-за информационной перегрузки.
Для решения данной для нас задачки я скачал практически все размещенные исследования, статьи и патенты по теме ИИ за крайние несколько лет. Они обхватывали разные системы искусственного ума, включая ChatGPT, Gemini и Perplexity. Потом я отобрал 54 более принципиальных и нужных примера. Я систематизировал результаты всякого из их и соотнес их, чтоб выявить более похожие и нередко цитируемые наблюдения.
Выставленные ниже причины ранжирования в ИИ ответах основаны на настоящих данных из размещенных тестов и исследовательских работ. Сила всякого «фактора» определяется последующими аспектами:
-
Воспроизводимость. Сколько раз один и этот же итог наблюдался в различных исследовательских работах? Также, как размеренны результаты – положительные либо отрицательные – в различных исследовательских работах.
-
Сила доказательств. К примеру, исследование, охватившее 50 миллионов запросов, имеет больший вес, чем исследование, обхватывающее 10 запросов.
-
Официальная поддержка. Наличие либо отсутствие официальной документации, технических черт либо патентов, подтверждающих соответствие данного фактора заявленным характеристикам.

Причины ранжирования цитирований в ИИ – термическая карта доказательств
Опосля обработки всех этих данных я вручную присвоил баллы на базе обозначенных критериев, используя искусственный ум для уточнения цифр. Баллы варьируются от 9,5 до 2.
Ниже представлены более обоснованные свойства контента, которые обеспечивают цитирование в ИИ.
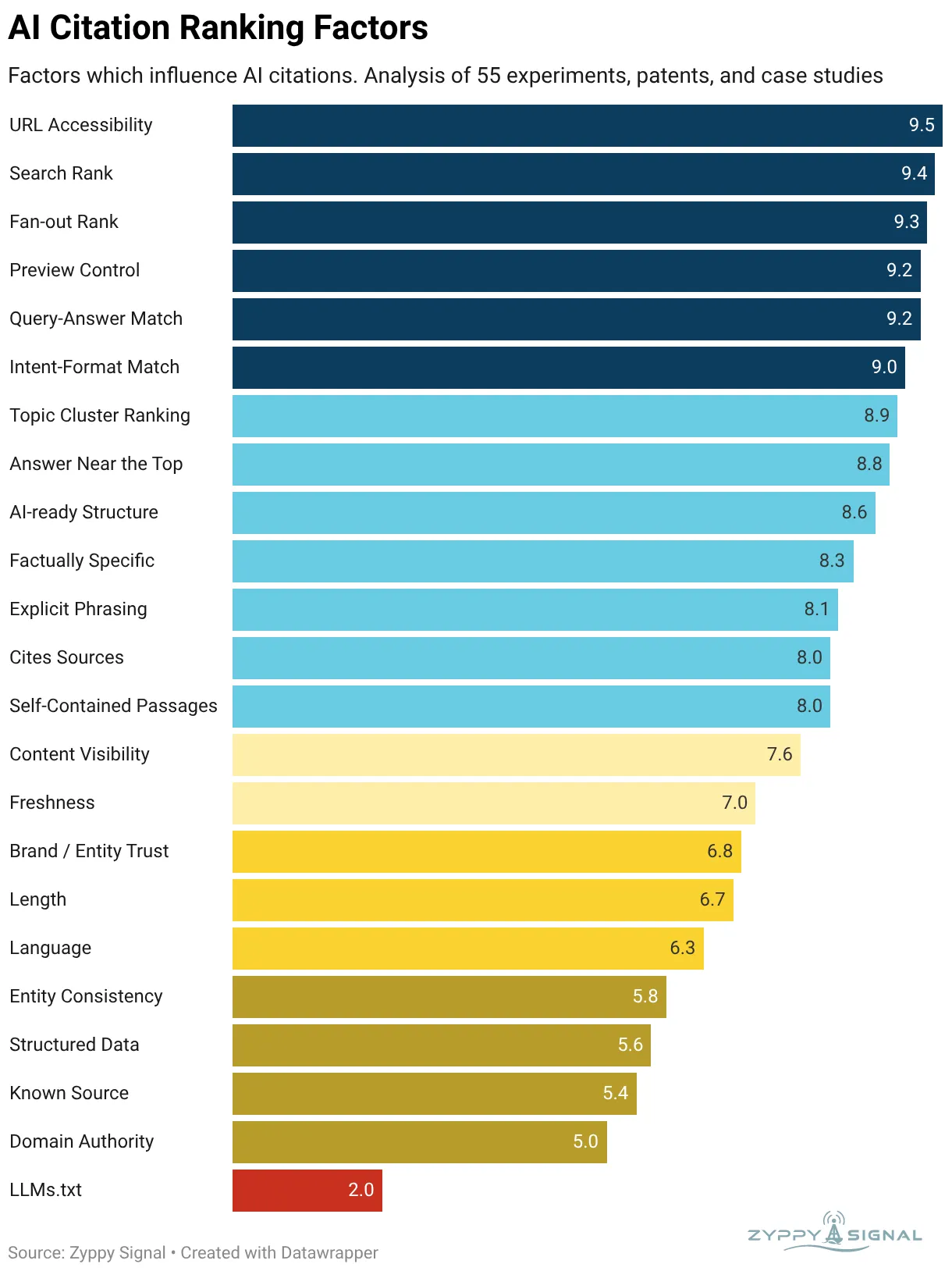
Примечание: это не «причины ранжирования» в классическом смысле. Это свойства, коррелирующие с цитированием ИИ в нескольких исследовательских работах. Корреляция не значит причинно-следственную связь. Все ошибки в данных либо объяснениях являются только моей ответственностью. Для наиболее глубочайшего осознания этих причин я рекомендую для вас ознакомиться с начальными статьями.
Короткое резюме
Хотя данные свидетельствуют о том, что определенные способы могут повысить количество упоминаний в ИИ-ответах, большая часть критически принципиальных причин соответствуют обычным способам SEO. Это принципиально, так как ведутся бессчетные дебаты о том, требуется ли для оптимизации видимости в ИИ иной набор инструментов.
Мои данные разрешают создать таковой вывод: выигрываем в SEO – выигрываем в цитировании ИИ (почти всегда, с доп шагами).
Описание причин ранжирования в ИИ-ответах
1. Доступность URL-адресов
Оценка: 9,5.
Определение: страничка доступна и индексируется во время обучения нейросети либо подготовки ответа.
Это базисные принципы SEO, используемые к системам искусственного ума. Обычно, для того чтоб ИИ мог на него ссылаться, URL-адрес должен быть доступен и индексироваться или во время обучения, или на шаге подготовки ответа.
Тем не наименее, ситуация существенно усложнилась, так как компании, специализирующиеся искусственным умом, добавляют больше пользовательских агентов для сканирования сайтов (OAI-SearchBot, GPTBot, Гугл-Extended и т. д.), а такие компании, как Cloudflare, дают средства защиты от парсинга сайтов при помощи ИИ. В итоге сделалось проще, чем когда-либо, исключать странички из систем ИИ и снижать возможность их упоминания в поисковых системах.
2. Рейтинг в поисковой выдаче
Оценка: 9,4.
Определение: как URL-адрес ранжируется по четкому запросу.
Бессчетные исследования выявили четкую связь меж высочайшими позициями в «классическом» поиске и упоминаниями в AI Overviews. Компания Ahrefs нашла, что 38% упоминаний AI Overviews приходится на 1-ые 10 поисковых результатов Гугл. Если же результаты выходят за границы первой 10-ки, то пересечение возрастает.
Ситуация с ChatGPT труднее, так как он не стопроцентно открывает источники поиска, но AirOps нашел сильную связь меж «рейтингом поиска» и цитированиями из ChatGPT.
3. Рейтинг по связанным запросам в выдаче
Оценка: 9,3.
Определение: как URL-адрес ранжируется для связанных запросов с расширением поисковой выдачи.
Кроме ранжирования по основному запросу, поисковые машины на базе ИИ делают огромное количество доп запросов, чтоб дополнить и доказать свои ответы. Бессчетные данные свидетельствуют о точной связи меж высочайшим рейтингом по доп запросам и получением упоминаний в поисковых системах на базе ИИ.
Проработать все SEO-факторы, которые влияют на цитирование ИИ, поможет PromoPult. В модуле «Поисковое продвижение» есть тип проектов «Динамическое SEO». Его преимущество в том, что умный метод не только лишь автоматом подбирает слова для продвижения, да и повсевременно анализирует семантику: выявляет, какие ключи приносят трафик и конверсии, неэффективные фразы подменяет на новейшие. Для вас не надо без помощи других заниматься подбором и актуализацией семантического ядра. За вас это сделает PromoPult. Доборная функция – можно настроить собственные правила ротации главных слов.
Протестировать эффективность технологии можно безвозмездно за 2 недельки.
4. Управление подготовительным просмотром
Оценка: 9,2.
Определение: элементы управления подготовительным просмотром, такие как директива «nosnippet», могут влиять на видимость.
А именно, для Гугл и Bing элементы управления подготовительным просмотром – это директивы, дозволяющие обладателям веб-сайтов и веб-мастерам надзирать, какую часть странички поисковые машины могут показывать в сниппетах и на неких площадках ИИ. Примерами являются «nosnippet» и «data-nosnippet». Ограничение видимости определенного текста может понизить видимость в ИИ.
5. Релевантность запросу
Оценка: 9,2.
Определение: содержимое странички буквально соответствует запросу – как основному, так и расширенному.
Бессчетные исследования задокументировали «семантическую близость» меж ответом ИИ и цитируемым контентом. Это нередко значит, что заглавия страничек, подзаголовки и содержание буквально соответствуют как запросу в поисковике, так и ответу ИИ.
6. Соответствие интенту
Оценка: 9.
Определение: тип странички соответствует цели запроса, к примеру, применен перечень для запросов вида «топ-n сущностей».
Поисковые машины на базе искусственного ума, обычно, отдают предпочтение статьям, формат контента которых идеальнее всего подступает для запроса в поисковике. К примеру, для запросов типа «наилучшие» («наилучшие пробиотики для парней») быть может лучше перечень либо сравнительная таблица, тогда как для запросов типа «как создать» («как выстроить скворечник») почаще будет предложено пошаговое управление.
Может быть, это просто артефакт поискового рейтинга либо рейтинга распространения.
7. Ранжирование направленных на определенную тематику кластеров
Оценка: 8,9.
Определение: степень ранжирования веб-сайта по нескольким запросам (главный + доп).
Это увлекательная, но обычная для осознания теория. Сущность в том, что ранжирование по нескольким связанным запросам наращивает ваши шансы быть процитированным хотя бы один раз. Методика RRF Top-n Playbook, хотя и непростая в техническом плане, была одним из моих возлюбленных экспериментальных методов разъяснения этого явления.
8. Ответ в высшей части странички.
Оценка: 8,8.
Определение: принципиальный контент, размещенный в высшей части странички, с большей вероятностью будет цитироваться.
Системы искусственного ума не обрабатывают весь текст на страничке идиентично. Дэн Петрович показал, как Гугл Gemini употребляет серьезное ограничение на количество запросов к URL-адресу, и контент в высшей части странички с большей вероятностью будет обработан. Это подтверждают и несколько остальных исследовательских работ.
9. Структура, готовая к использованию ИИ
Оценка: 8,6.
Определение: контент отформатирован таковым образом, чтоб ИИ мог просто извлекать и осознавать информацию.
Исходя из того, что поисковые машины на базе искусственного ума обычно не загружают всю страничку полностью, учтите, что они разбивают странички на разделы перед загрузкой. Если ваш контент не имеет точной структуры, это может усложнить задачку.
Это не означает, что для вас необходимо «разбивать» собственный контент на маленькие фрагменты; просто обеспечьте четкую структуру с заголовками, разделами, таблицами и т. д. Почти все исследования выявили четкую связь меж таковыми функциями и цитированием в ответах ИИ.
10. Конкретика и факты
Оценка: 8,3.
Определение: странички и фрагменты, содержащие определенные, поддающиеся проверке факты.
Так как ссылки на источники вводятся для доказательства определенных утверждений в самом ответе ИИ, целенаправлено подкрепить это определенными фактами, на которые ИИ может ссылаться. Утверждения типа «Взрослым необходимо много белка» не так нередко цитируются, как «Специалисты советуют 0,8 грамма белка на килограмм массы тела».
11. Точная формулировка
Оценка: 8,1.
Определение: определенные утверждения важнее расплывчатых заявлений.
Подобно принципу «фактической конкретности», системы искусственного ума, похоже, предпочитают наиболее определенные фразы без уклончивых формулировок. К примеру, фраза «Некие люди предпочитают глицинат магния, а остальные употребляют цитрат либо треонат…» еще слабее, чем «Глицинат магния – наилучший выбор для сна».
12. Ссылки на источники
Оценка: 8.
Определение: факты подкреплены ссылками на источники.
Несколько исследовательских работ проявили, что факты, для которых верно указаны источники, почаще цитируются ИИ. Это разумно, так как системы искусственного ума стремятся генерировать ответы и ссылки, которые они могут доказать.
На практике это не значит, что для вас необходимо добавлять ссылки на источники ко всему вашему контенту, но было бы уместно показать, как вы пришли к принципиальным выводам.
13. Самодостаточные фрагменты текста
Оценка: 8.
Определение: принципиальные утверждения могут существовать сами по для себя, без доп контекста.
Понятие «самодостаточные фрагменты текста» значит, что главные факты либо моменты стопроцентно излагаются в предложениях либо блоках текста.
К примеру, если вы скажете: «Этот ингредиент имеет наиболее весомые подтверждения», система искусственного ума будет обязана рассматривать смысл, исходя из остальных фрагментов текста. Какой ингредиент? Какие подтверждения? Но если вы скажете: «Воздействие глицината магния на здоровье сердца доказано 137 исследованиями», информация будет конкретной и самодостаточной.
14. Видимость контента
Оценка: 7,6.
Определение: принципиальная информация находится в видимом HTML-тексте, а не укрыта.
Современные интернет-страницы могут содержать много текста, который не сходу виден, по последней мере, без огромного количества JavaScript либо с требованием к юзерам кликать по элементам div и tabs. Издавна понятно, что даже Гугл, похоже, не так отлично ранжирует контент, если он нечетко виден на страничке, и, судя по всему, системы искусственного ума делят это предубеждение.
15. Свежесть
Оценка: 7.
Определение: как животрепещуща информация.
Актуальность – узнаваемый фактор ранжирования в SEO, и несколько исследовательских работ выявили корреляцию меж актуальностью документа и цитированием в результатах ИИ. Как и в классическом поиске, актуальность, по-видимому, варьируется зависимо от запроса. Вопросец о недавнешнем спортивном матче востребует наиболее животрепещущей инфы, чем вопросец о английской истории.
16. Доверие к бренду/организации
Оценка: 6,8.
Определение: как отлично система искусственного ума понимает бренд либо сайт и как ей доверяет.
Всё почаще системы искусственного ума, похоже, стремятся употреблять наиболее достоверные источники инфы. Это значит, что то, что они уже знают о вас, может влиять на уровень их доверия либо на то, будут ли они находить у вас информацию. В случае запроса, связанного со здоровьем, система ИИ с большей вероятностью доверится известной поликлинике, чем анонимному мед блогу. Гугл работает аналогичным образом, потому, возможно, есть некое совпадение.
17. Длина контента
Оценка: 6,7.
Определение: длина текста в словах.
Бессчетные исследования изучали корреляцию меж длиной контента и количеством цитирований ИИ. Хотя большая часть из их проявили, что наиболее длиннющий контент, обычно, показывает наилучшие результаты, данные были противоречивыми. Несколько исследователей отметили, что наиболее длиннющий контент также понижает возможность того, что поисковые машины ИИ сумеют получить доступ ко всему вашему контенту.
18. Язык
Оценка: 6,3.
Определение: язык контента.
Исследования выявили очевидную предвзятость в отношении языка – а время от времени и места – задаваемого вопросца. Вопросец, данный на французском языке человеком из Франции, с большей вероятностью будет содержать французские цитаты.
19. Согласованность сущностей
Оценка: 5,8.
Определение: внедрение единообразных заглавий для продуктов, брендов, людей и т. д.
Согласованность сущностей значит внедрение единых правил именования для брендов, людей, товаров и т. д.
К примеру, я мог бы написать: «Zyppy производит программное обеспечение для SEO, которое помогает рекламщикам занимать высочайшие позиции в поисковой выдаче». Это еще понятнее, чем «Zyppy производит SEO-программное обеспечение. Мое программное обеспечение помогает рекламщикам занимать высочайшие позиции в поисковой выдаче». 1-ый вариант понятнее как для поисковых машин, так и для юзеров.
20. Структурированные данные
Оценка: 5,6.
Определение: страничка содержит разметку для идентификации сущностей и извлечения контента.
Посреди SEO-специалистов ведутся горячие споры о использовании структурированных данных для оптимизации контента под ИИ. Хотя это правда, что LLM (огромные языковые модели) обычно не употребляют микроразметку в процессе обучения, есть ограниченные подтверждения того, что они, по последней мере, могут созидать ее при поиске.
Фактически каждое исследование, изучающее микроразметку и цитирование в ИИ, выявляет положительную связь. Эффект обычно невелик, но он умопомрачительно устойчив во всех исследовательских работах.
21. Узнаваемый источник
Оценка: 5,4.
Определение: URL-адрес уже известен движку ИИ благодаря обучающим данным.
Время от времени (достаточно нередко, по сути) ИИ цитирует URL-адрес просто поэтому, что понимает о нем из имеющихся обучающих данных. Для ChatGPT и Perplexity это наиболее приемлимо, так как дозволяет обойти обыденную фазу сравнения/поиска, что приводит к возникновению ссылок, которые больше не есть.
22. Авторитет домена
Оценка: 5.
Определение: показатель популярности сайта, основанный на количестве ссылок.
В нескольких исследовательских работах изучалась связь меж авторитетом домена и цитированием, приобретенным при помощи ИИ. Хотя в почти всех из их была найдена связь, она нередко оказывалась слабенькой.
23. LLMs.txt
Оценка: 2.
Определение: на веб-сайте расположен файл LLMs.txt для движков искусственного ума.
Если честно, я не уверен, что в почти всех из этих исследовательских работ совершенно рассматривалось воздействие файлов LLMs.txt. Тем не наименее, нам не удалось отыскать никаких достоверных доказательств либо тестов, демонстрирующих какое-либо воздействие файлов LLMs.txt на цитирование в контексте искусственного ума.
Шаги для роста количества цитирований в ИИ
В итоге, для вас не нужна совсем новенькая стратегия SEO, чтоб получить упоминания в поисковых результатах, но вы сможете скорректировать некие способы и наиболее отлично ввести ряд остальных SEO-стратегий.
Меж классическими SEO-сигналами и сигналами цитирования, приобретенными при помощи ИИ, существует существенное совпадение.
Не считая того, почти все из этих причин при правильном внедрении могут сделать лучше пользовательский опыт на вашей страничке, что обязано быть ценностью номер один.
Если б нам пришлось их суммировать, они могли бы звучать так: релевантность, доверие, авторитетность по теме и извлекаемость – все эти сигналы должны соответствовать современным представлениям о SEO. Некие технические детали изменяются, но мы как и раньше можем сосредоточиться на разработке прекрасного пользовательского опыта.