SSR в SPA есть, а SEO нет
Вы перевели интернет-магазин на Next.js либо Nuxt.js, подключили SSR, все «рендерится на сервере», но органический трафик не вырастает. В Гугл Search Console видно частичную индексацию, а в Yandex Веб-мастере практически пусто. Знакомо?
Неувязка не в самом SPA. Неувязка – в качестве HTML, который отдается с сервера. Наличие SSR – это только техно возможность. Чтоб она работала на SEO, SSR-верстка обязана быть полной, семантически корректной и лишенной обычных ошибок.
Обычные ошибки SPA
Разберем девять критичных заморочек, которые делают веб-сайт «невидимым» для поисковиков даже при формальном наличии SSR. В особенности животрепещуще для проектов, нацеленных на российскую аудиторию и продвигающихся в Yandex’е.
- Ссылки без < a >: веб-сайт становится «непролазным»
Сущность ошибки
В SSR-HTML заместо семантической ссылки < a href="/product/123" > употребляются < div >, < span >, < button > и обработчики кликов (onClick, router.push()).
Почему это критично
Обе поисковые машины – Гугл и Yandex – полагаются на тег < a > с атрибутом href как на главный сигнал навигации снутри веб-сайта. Лишь такие элементы участвуют в построении карты сканирования; передают anchor text, который впрямую влияет на текстовую релевантность мотивированной странички; разрешают боту осознать иерархию и структуру веб-сайта, распределить ссылочный вес.
Если ссылка реализована без < a >, она быть может проигнорирована при сканировании, даже если работает в браузере. В итоге страничка не получает anchor text от остальных разделов, не участвует во внутренней перелинковке и теряет релевантность по мотивированным запросам.
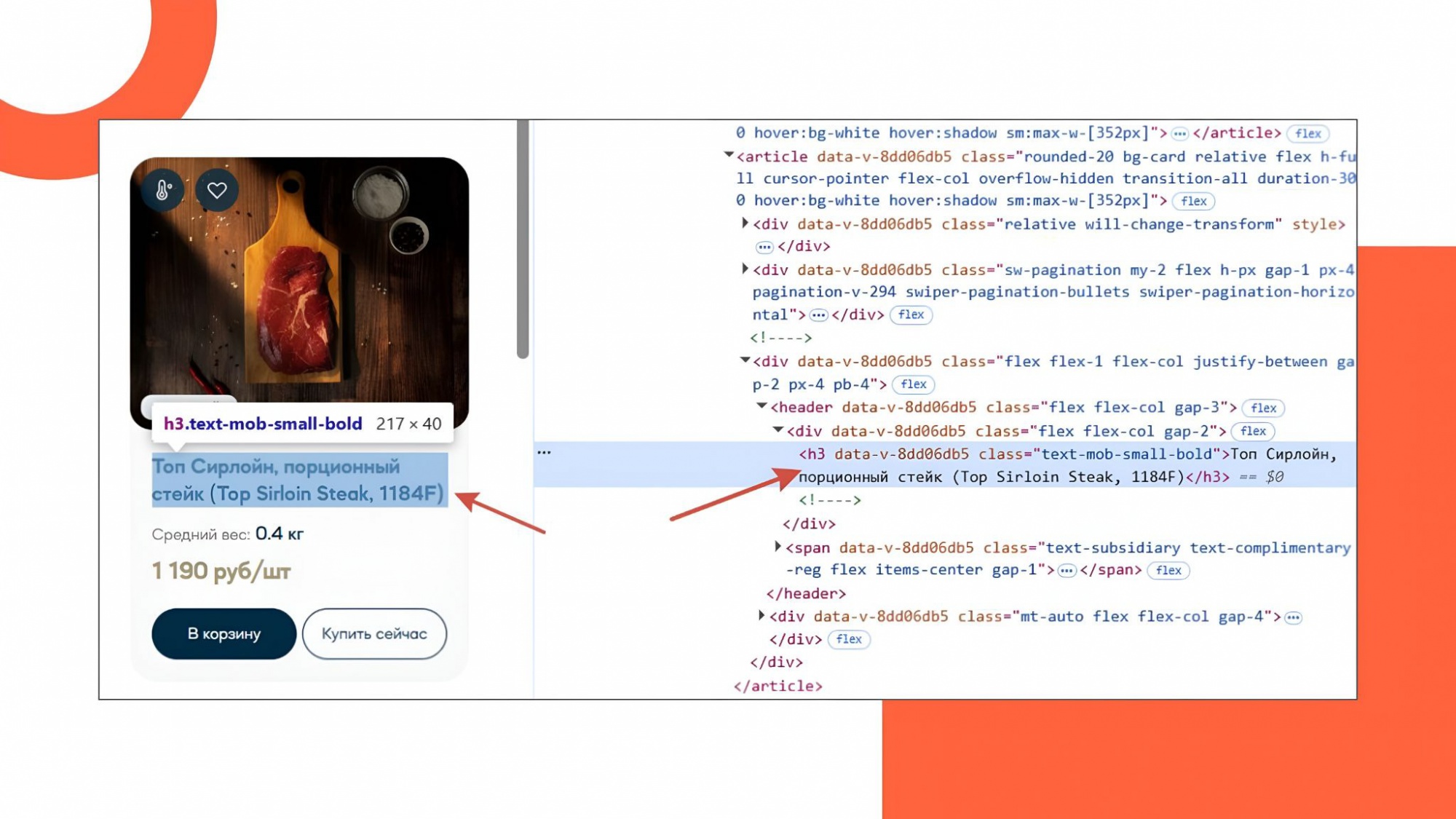
Пример отсутствия тега < a > в коде
Sitemap.xml помогает найти URL, но не подменяет внутренние ссылки. Он не дает контекста, не сформировывает иерархию и не влияет на осознание темы.
Но даже наличие тега < a > не является страховкой от ошибки.

Тег < a > есть, а атрибута href нет
Верный подход
Внутренние ссылки на веб-сайте должны применять семантический тег < a href > с корректным значением адреса. Даже если зрительно элемент ведет на страничку через < div >, < span > либо < button > с обработчиком клика, поисковые боты его не распознают.
- Различный HTML в SSR для ПК (Персональный компьютер — компьютер, предназначенный для эксплуатации одним пользователем) и мобильных устройств: отсутствие единой структуры
Сущность ошибки
На веб-сайте употребляется раздельная верстка: сервер дает различные HTML-структуры для десктопных и мобильных устройств. Это не адаптивность через CSS, а практически две различные странички.
Приведем обычные примеры различий меж версиями веб-сайта.
-
Пагинация. В десктопной версии есть обычная навигация по страничкам – ссылки вроде < a href="/page/2" >2< /a > и < a href="/page/3" >3< /a >. В мобильной версии ее подменяют нескончаемой лентой: юзер просто скроллит перечень, а ссылок на остальные странички при всем этом нет.
-
Хлебные крошки. На рабочем столе, отображается полная цепочка навигации со ссылками на все уровни разделов. В мобильной версии она облегчена: к примеру, остается лишь клавиша «Вспять» либо укороченная цепочка, где часть уровней совершенно отсутствует в DOM.
-
Меню. В десктопной версии это обычно выпадающее меню с разделами. В мобильной – просто ссылка, ведущая на отдельную страничку «Каталог».
Почему это критично
Гугл употребляет mobile-first indexing, для него главный является мобильная версия. Yandex почаще сканирует десктопную версию, в особенности если она содержит больше контента. Если в одной из версий нет ссылок на пагинацию, поисковик не может перейти на вторую и следующие странички группы.
Это становится критической неувязкой, если sitemap.xml отсутствует либо не полный. В таковой ситуации пагинация – единственный путь для поисковика добраться до глубочайших карточек. Если ее нет в SSR, то ассортимент обрезается: индексируются лишь продукты с первой странички группы.
Аналогично, если в одной из версий отсутствуют промежные звенья хлебных крошек, то пропадает anchor text для категорий, передача веса по иерархии и контекст для расчета текстовой релевантности.
При помощи инструмента Diff Checker можно сопоставить код страничек для различных устройств.

Верный подход
Чтоб избежать таковых заморочек, лучше сходу закладывать несколько базисных принципов в архитектуру веб-сайта.
Во-1-х, по способности применять адаптивную верстку, когда для всех устройств отдается один и этот же HTML. Это понижает риск того, что поисковый бот увидит структуру страничек по другому, чем юзер.
Во-2-х, если навигация на рабочем столе и в мобильной версии принципно различается, принципиально сохранять семантические ссылки в HTML. К примеру, пагинация обязана оставаться реализованной через < a href >, даже если зрительно она укрыта. То же касается и хлебных крошек: в DOM лучше оставлять полную цепочку разделов.
Еще одна страховка – животрепещущий sitemap.xml с прямыми ссылками на все продукты и странички каталога. Он помогает поисковым системам отыскивать странички даже в тех вариантах, когда навигация на веб-сайте работает неидеально.
И в конце концов, стоит часто инспектировать, совпадает ли структура ссылок в начальном HTML для десктопной и мобильной версии. Это обычная проверка, которая нередко помогает впору увидеть препядствия с индексируемостью.
- Контент в аккордеонах, вкладках и FAQ отсутствует в SSR
Сущность ошибки
Частая неувязка – контент, который подгружается лишь на стороне клиента. К примеру, тексты во вкладках «Описание», «Свойства», «Гарантия», «FAQ» могут появляться на страничке уже опосля загрузки, через JavaScript. В итоге в SSR-версии странички этого контента просто нет.
Если поглядеть начальный HTML, картина обычно смотрится так: контейнеры под описание продукта либо блоки с товарными советами находятся, но остаются пустыми. Вкладки с чертами и отзывами могут совершенно отсутствовать в разметке, поэтому что данные для их загружаются асинхронно на клиенте.
Схожая ситуация возникает с контентом снутри аккордеонов, вкладок либо выпадающих списков. Часто он подгружается лишь опосля взаимодействия юзера – к примеру, при клике на вкладку либо раскрытии блока. Для поисковых машин таковой контент может оказаться труднодоступным либо индексироваться существенно ужаснее.
Почему это критично
Поисковые машины – и Гугл, и Yandex – индексируют контент, сокрытый через CSS (display: none, visibility: hidden), если он находится в начальном HTML-коде странички. Критичная разница возникает, когда текст отсутствует в SSR-HTML и подгружается динамически лишь опосля выполнения JavaScript на клиенте: Гугл может выполнить скрипты и проиндексировать таковой контент, но с задержкой (в рамках 2-ой волны индексации) и без гарантий, потому что рендеринг зависит от доступности ресурсов краулера. Yandex наименее жестко делает клиентский JavaScript, потому контент, которого нет в исходном HTML, с высочайшей вероятностью не будет проиндексирован. В итоге понижается релевантность, отсутствуют доверительные сигналы.
Верный подход
Весь принципиальный контент должен быть в SSR-HTML, даже если вначале он укрыт.
«Сокрытый» не означает «отсутствующий» – для SEO принципиально присутствие в DOM. Если API недоступен на сервере, используйте кеширование ответов на стороне сервера.
- Lazy-loading критичного контента в SSR
Сущность ошибки
Блоки ниже первого экрана (отзывы, достоинства, сопоставления) удалены из SSR ради «убыстрения» начальной загрузки. Нередко совместно с текстом через lazy-load отдают и изображения, включая основное фото продукта.
Почему это критично
Таковая архитектура влияет не только лишь на индексируемость, да и на технические метрики веб-сайта.
Индексация. Если контент возникает лишь опосля взаимодействия юзера, к примеру, опосля скролла либо клика по вкладке, то поисковые боты могут его просто не узреть. Для Yandex’а это в особенности критично: бот не гарантирует выполнение сценариев, требующих действий юзера, потому контент, которого нет в начальном HTML, с высочайшей вероятностью не попадет в индекс.
Гугл в схожих вариантах может проиндексировать контент позднее, при рендеринге. Но это значит задержку: странички подольше возникают в поиске, а часть сигналов учитывается не сходу. В итоге оба поисковика могут созидать страничку в усеченном виде, что понижает ее оценку полезности.
Core Web Vitals. Подгрузка контента уже опосля отрисовки странички нередко приводит к сдвигам макета. Это впрямую усугубляет показатель CLS.
Отдельная всераспространенная ошибка – когда основное изображение странички отмечают атрибутом loading=»lazy». В этом случае браузер откладывает его загрузку, из-за что замедляется отображение главного элемента странички и усугубляется метрика Largest Contentful Paint (LCP).
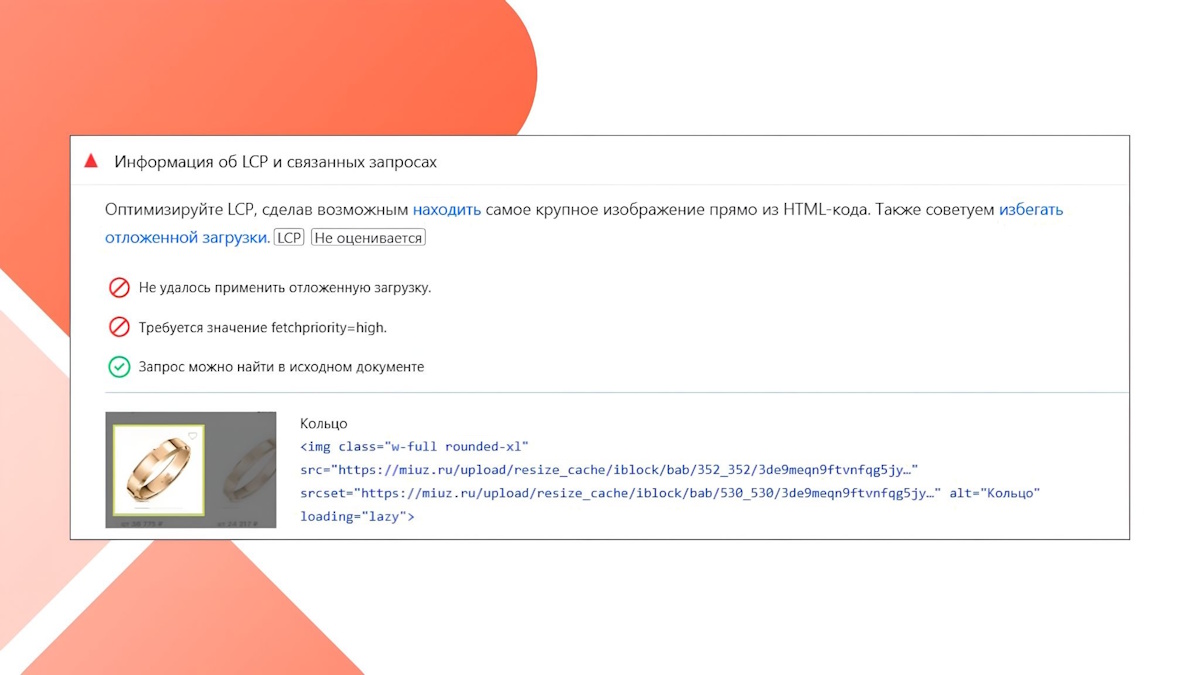
Пример: большие изображения с атрибутом loading=»lazy», показатель LCP нехороший
Верный подход
Чтоб избежать схожих заморочек, принципиально верно настроить работу ленивой загрузки. Lazy-load имеет смысл применять лишь для томного медиаконтента за пределами первого экрана, к примеру, для изображений либо видео. Текстовые блоки и коммерчески весомый контент должны сходу находиться в SSR-версии странички.
Очередной принципиальный момент – предотвращение сдвигов макета. Для этого пространство под изображения и остальные элементы лучше заблаговременно резервировать в CSS. Тогда при их загрузке страничка не будет «прыгать», а характеристики стабильности верстки останутся в норме.
- В SSR отсутствуют стоимость и CTA-кнопки
Сущность ошибки
Стоимость, клавиши «Приобрести» и «В корзину» пустые либо отсутствуют в SSR, потому что подгружаются лишь опосля гидратации.
Почему это критично
Для Yandex’а наличие цены и CTA – главные коммерческие сигналы. Их отсутствие понижает коммерческую релевантность, в особенности по запросам «приобрести» и «стоимость».
Для Гугл отсутствие этих частей ослабляет E-E-A-T причины (Experience, Expertise, Authoritativeness, Trustworthiness). Поисковик ужаснее распознает веб-сайт как надежный интернет-магазин.
В итоге страничка теряет позиции в коммерческой выдаче, расширенный сниппет в Гугл по схеме https://schema.org/Product.
Верный подход
Принципиально, чтоб главная коммерческая информация была доступна уже в SSR-версии странички. К примеру, базисную стоимость продукта лучше отдавать сходу в HTML, хотя бы в формате «от 10 000 руб.».
Клавишу «В корзину» также стоит включать в начальную разметку. Даже если до загрузки JavaScript она неактивна, сам элемент должен находиться в HTML – это помогает поисковым системам корректно распознавать коммерческую функцию странички.
Добавочно полезно добавлять микроразметку, к примеру, Product и Offer, тоже на уровне SSR. Это упрощает поисковым системам интерпретацию данных о товаре и увеличивает шансы на корректное отображение странички в поисковой выдаче.
- В SSR врубается излишний, нерелевантный контент
Сущность ошибки
В SSR-HTML автоматом вставляется большой юридический либо шаблонный текст в поп-апе, не связанный с главный темой странички:
-
политика обработки индивидуальных данных (полный текст на каждой страничке);
-
пользовательское соглашение;
-
условия доставки, возврата, гарантии дублируются в полном объеме на всех карточках продуктов.
Принципиально! Извещения о cookie – исключение. Их наличие не вредит SEO, а быстрее подтверждает соответствие требованиям прозрачности.
Почему это критично
Поисковики анализируют весь текст в HTML, включая сокрытые блоки. Большенный размер нерелевантного контента размывает текстовую релевантность странички (к примеру, «iPhone 15» пропадает посреди 2000 символов о политике конфиденциальности), понижает долю неповторимого мотивированного текста, может воздействовать на систематизацию странички как малополезной, в особенности в Yandex’е.
В итоге вырастает риск утраты релевантности по мотивированным запросам, усугубляется ранжирование в конкурентных нишах.
Верный подход
Полный текст юридических документов лучше располагать на отдельных страничках, а не выводить его в футере либо модальных окнах на любом URL. Это делает структуру веб-сайта чище и не перегружает HTML излишним контентом.
Если модальное окно все-же нужно, его содержимое можно подгружать уже на стороне клиента. Основное – не включать таковой контент в SSR, если он не несет SEO-ценности.
- Различные SSR-версии для Гугл и Yandex’а: мобильная для Гугл, десктопная для Yandex’а
Сущность ошибки
Время от времени команды пробуют «подстроить» веб-сайт под различных поисковых ботов на уровне SSR. К примеру, при User-Agent Googlebot (mobile) сервер дает мобильную версию странички с нескончаемой лентой и облегченной навигацией. А при User-Agent YandexBot – десктопную, где есть пагинация и наиболее полная структура ссылок.
На 1-ый взор это смотрится как разумный соглашение: любому поисковику показывается версия, которая лучше соответствует его особенностям. Но на практике таковой подход приводит к тому, что практически есть две различные модели веб-сайта. Это усложняет индексацию, диагностику ошибок и делает поведение страничек в поиске наименее прогнозируемым.
Почему это критично
Неувязка в том, что в таковой схеме поисковые машины начинают созидать различные версии веб-сайта.
Гугл получает мобильную страничку, где может не быть обычных частей навигации, к примеру, ссылок на пагинацию, полной цепочки хлебных крошек либо даже части продуктов в каталоге. Yandex, напротив, лицезреет десктопную версию с полной структурой разделов. Но при всем этом он не соображает, как веб-сайт смотрится для юзеров со телефонов, а конкретно мобильный трафик сейчас составляет огромную часть поисковых переходов.
Из-за этого усложняется и технический аудит. Практически приходится инспектировать не одну, а две различные SSR-версии веб-сайта, отслеживая, как любая из их отдается различным ботам.
Не считая того, возникает риск расхождений в индексации. Гугл может не узреть часть ассортимента, а Yandex – не учесть настоящие мобильные сценарии использования веб-сайта.
В итоге различные SSR-версии под различных поисковиков преобразуются в технический долг: поддержка становится труднее, поведение веб-сайта в поиске – наименее прогнозируемым, а риск утраты трафика – выше.
Верный подход
Лучше отдавать одну и ту же SSR-версию странички для всех устройств и поисковых ботов, используя адаптивную разметку через CSS.
Также полезно временами инспектировать сохраненные копии страничек в Гугл Search Console и Yandex Веб-мастере, чтоб убедиться, что главные элементы – цены, клавиши, навигация – находятся и индексируются корректно.
- Гидратация как источник «мигания» контента
Сущность ошибки
При использовании SSR сервер дает готовую разметку с контентом. Но при загрузке клиентского JavaScript начинается гидратация – процесс перехода от статичной странички к динамической. Если она реализована неправильно, фреймворк сбрасывает состояние компонент в «режим загрузки», и контент исчезает, сменяясь скелетонами. Потом, через несколько сотен миллисекунд, контент возникает опять.
Зрительно это смотрится так:
-
юзер лицезреет контент;
-
страничка «мигает»;
-
возникают скелетоны;
-
контент ворачивается.
Почему это критично
Googlebot сейчас основан на Chromium и при рендеринге страничек практически имитирует поведение обыденного юзера. Он фиксирует зрительные конфигурации на страничке, определяет Core Web Vitals в настоящем времени и оценивает плавность загрузки как показатель свойства. Иными словами, бот глядит на веб-сайт практически так же, как настоящий юзер, и учитывает это при ранжировании.

Результаты неправильной гидратации
Верный подход
Неправильная гидратация – это не попросту «косметический баг». Это прямой удар по метрикам свойства, которые Гугл употребляет для ранжирования. Исправление данной нам ошибки улучшает сразу и пользовательский опыт, и SEO-показатели.
- Отсутствие либо ошибки в rel=»canonical»
Сущность ошибки
В SSR-версии странички время от времени отсутствует тег < link rel="canonical" >, или он формируется неправильно, к примеру, указывается относительный путь либо возникает ошибка в URL при применении фильтров. В таковых вариантах поисковым системам труднее осознать, какая версия странички считается главный.
Почему это критично
Поисковые машины полагаются на каноническую ссылку, чтоб различать основную страничку от дублирующих, к примеру, при фильтрах, сортировках либо UTM-метках. Если тег < link rel="canonical" > отсутствует в начальном HTML, бот может проиндексировать альтернативную версию URL, что приводит к дублированию контента и понижает эффективность SEO.
Верный подход
Тег < link rel="canonical" > должен находиться в секции < head > SSR-версии странички. При всем этом принципиально применять абсолютный URL, к примеру, https://site.com/catalog, а не относительный путь.
Для основных страничек каждой версии канонический тег обычно ссылается на саму страничку. А для страничек с фильтрами либо сортировками, где контент не уникален, canonical показывает на основную категорию. Таковой подход помогает поисковикам верно определять основную версию странички и избегать заморочек с дублирующимся контентом.
Как проверить SSR-верстку: четыре надежных метода
Метод 1: начальный HTML под User-Agent поисковика
Один из методов проверить, что SSR-страница корректно отдается поисковикам, – применять начальный HTML под различными User-Agent. В Chrome DevTools это делается через вкладку Network:
-
Откройте меню ⋮ → More tools → Network conditions.
-
В разделе User agent снимите галочку Use browser default и вставьте подходящий User-Agent:
-
Googlebot (телефон):
Mozilla/5.0 (Linux; Android 10; K) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.гугл.com/bot.html) -
YandexBot:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)
-
Обновите страничку и в перечне запросов изберите главный HTML-документ (совпадает с URL странички).
-
На вкладке Response вы увидите незапятнанный HTML, приобретенный от сервера без конфигураций со стороны JavaScript.
Проверьте, что в этом HTML находятся: ссылки < a href="…" > для навигации, стоимость, описание, клавиши действий, текст в FAQ, свойствах и хлебных крошках.
Сравнивая ответы под различными User-Agent’ами, вы удостоверьтесь, что структура странички схожа для всех ботов и устройств – это главный момент для корректной индексации.
Метод 2: сохраненные копии в системах веб-мастеров
Для проверки того, как поисковые машины лицезреют страничку, можно применять интегрированные инструменты.
В Гугл Search Console откройте «Проверка URL» и изберите «Просмотреть тестированную страничку». В Yandex Веб-мастере используйте «Проверка странички» и перейдите на вкладку «Версия странички в поисковой базе».
Принципиально убедиться, что в обеих копиях находятся все главные элементы: навигация, цены, клавиши, тексты. Любые расхождения меж версиями говорят о вероятной дилемме с SSR либо подгрузкой контента.
Метод 3: Поиск по фрагменту контента
Чтоб проверить, что текстовый контент странички вправду индексируется, можно пользоваться поиском по неповторимому фрагменту из описания продукта, довольно 5-7 слов.
К примеру:
-
По всему веб-сайту: «неповторимый фрагмент текста» site:example.com
-
По определенной страничке: «неповторимый фрагмент текста» url:https://example.com/product/123 (URL должен быть в индексе).
Если поиск не возвращает результатов, то это сигнал, что контент может отсутствовать в SSR и не был проиндексирован поисковой машиной.
Метод 4: Тест без JavaScript
В Chrome DevTools можно проверить, что принципиальный контент доступен в SSR, даже если JavaScript отключен. Для этого:
-
Нажмите Cmd+Shift+P (Windows: Ctrl+Shift+P) и введите Disable JavaScript, потом изберите подобающую опцию.
-
Обновите страничку.
Если страничка при всем этом остается читаемой и навигируемой, означает, главный контент находится в SSR. Если же заместо описания и инфы о товаре видна пустота, это сигнал, что SEO-значимый контент загружается лишь на клиенте и не попадает в начальный HTML.
Для чего необходимо работать с SSR: настоящие кейсы
Чемодан 1
Важная часть контента карточки продукта отсутствовала в SSR и не попадала в HTML, который получал поисковый бот. В итоге поисковик не лицезрел ряд главных частей странички:
-
отзывы о товаре;
-
подробную информацию о работающей скидке либо акции;
-
клавишу «Добавить в корзину»;
-
блок с критериями доставки;
-
товарные советы («Вас может заинтриговать»).
Опосля исправления позиции стали лучше.
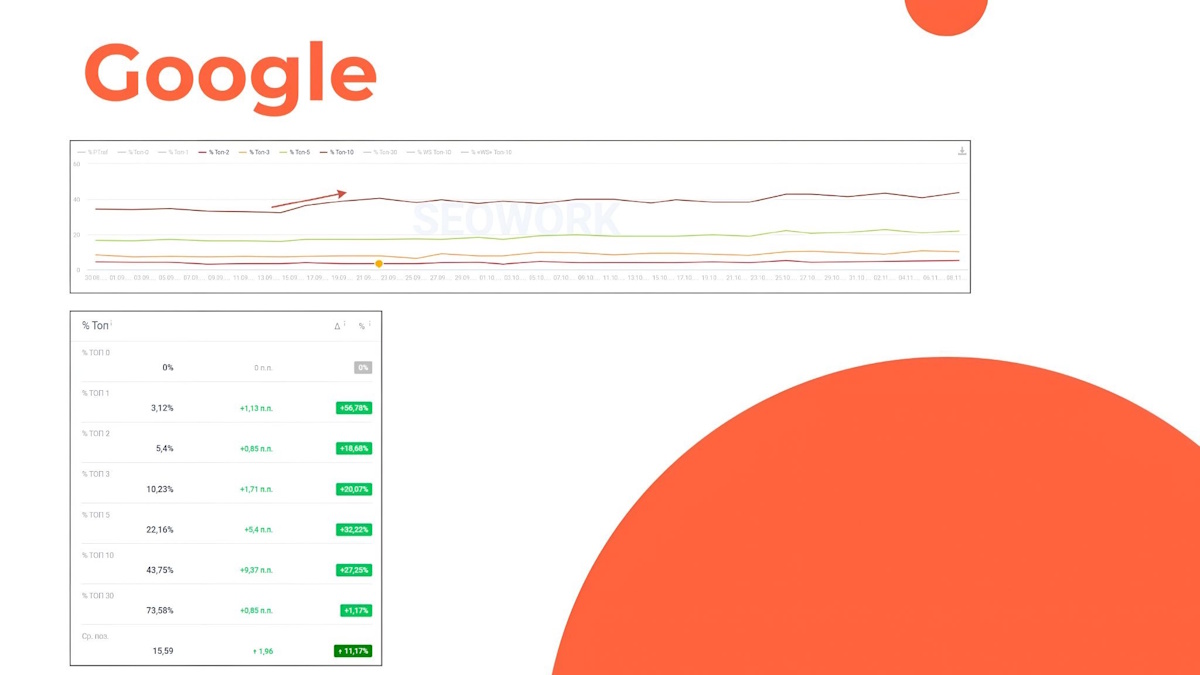
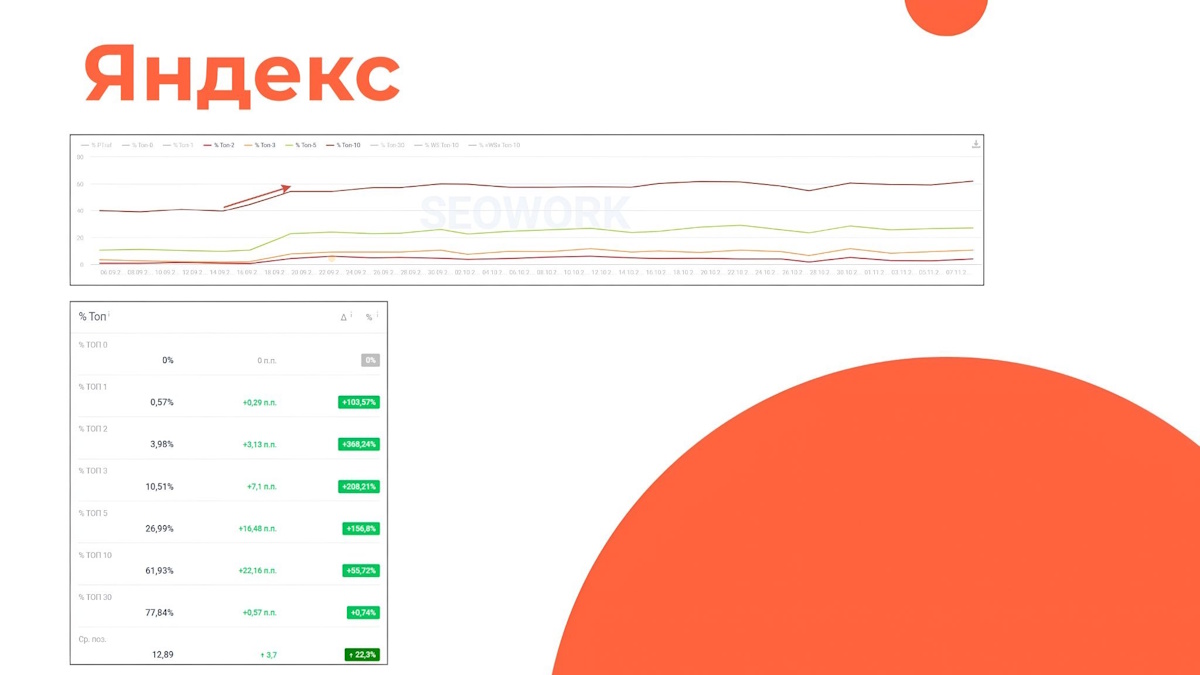
Трафик без бренда
Чемодан 2
Цены в каталоге и клавиша «В корзину» в SSR отсутствовали, подгружаясь лишь на клиенте.
Опосля исправления позиции в Yandex’е выросли.

Чемодан 3
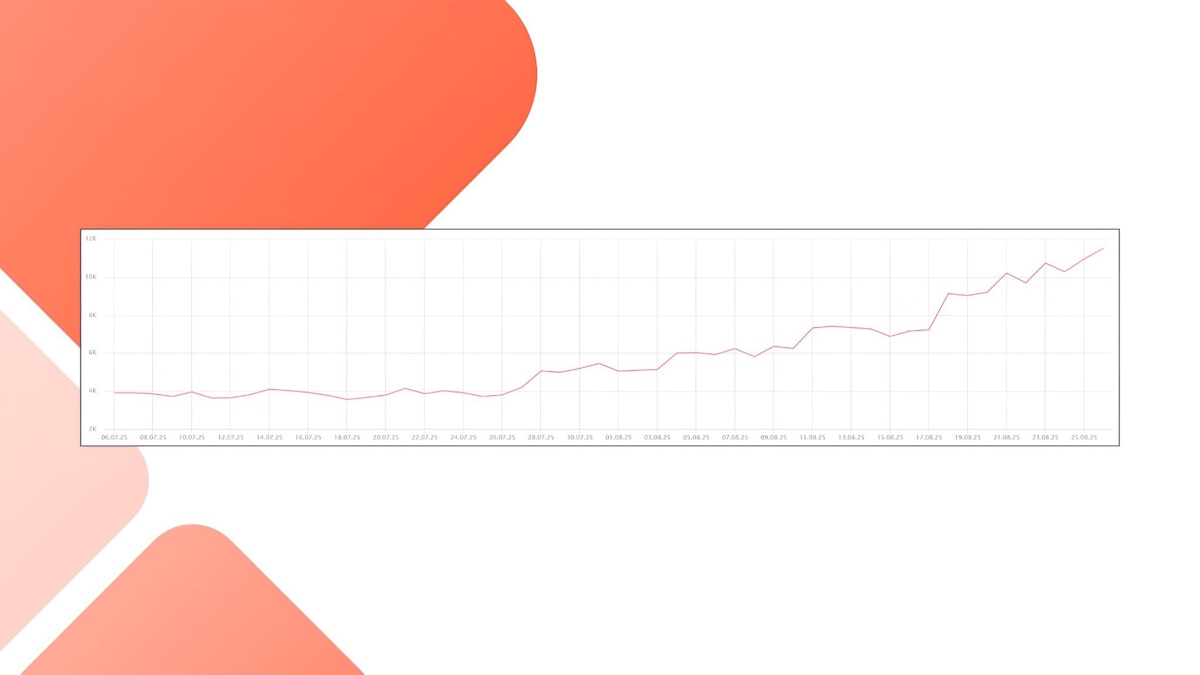
Часть перелинковки на выборки была укрыта под клавишей «Показать еще» и не подтягивалась в SSR.
Опосля прибавления ссылок из перелинковки в SSR-версию позиции страничек подборок выросли.
Чемодан 4
В хлебных крошках не выводилась вся цепочка навигации, лишь ссылка на страничку «Каталог».
Опосля исправления видимость категорий выросла и в Yandex’е, и в Гугл.
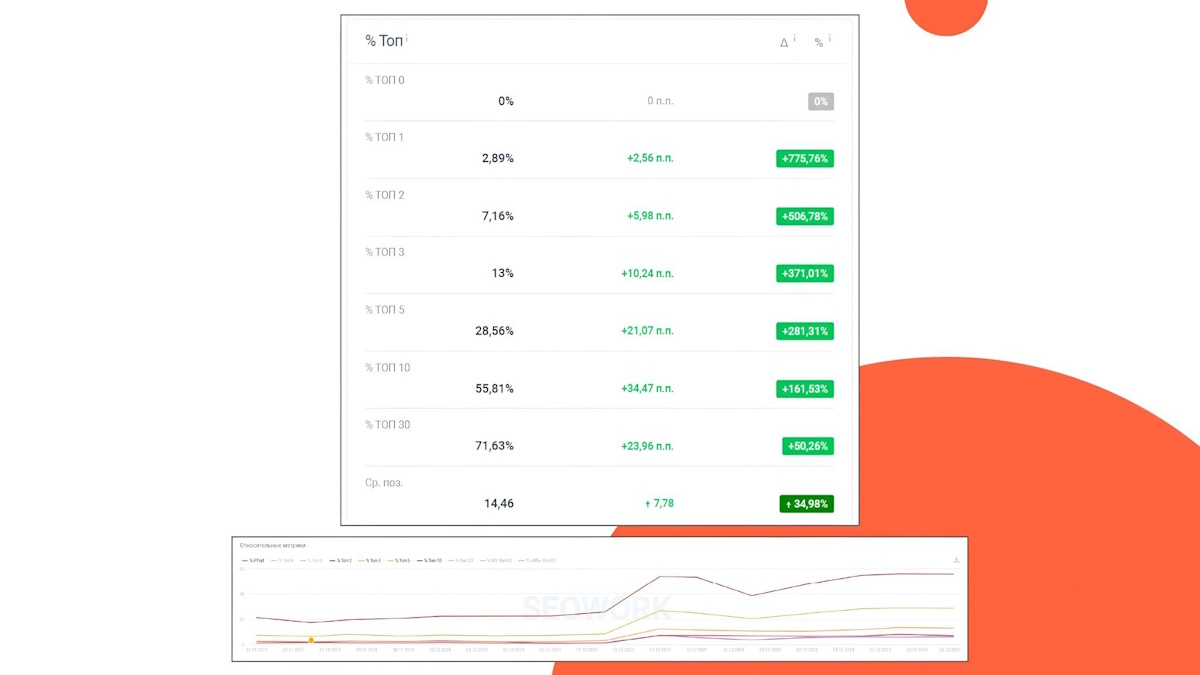
Рост позиций в Yandex’е
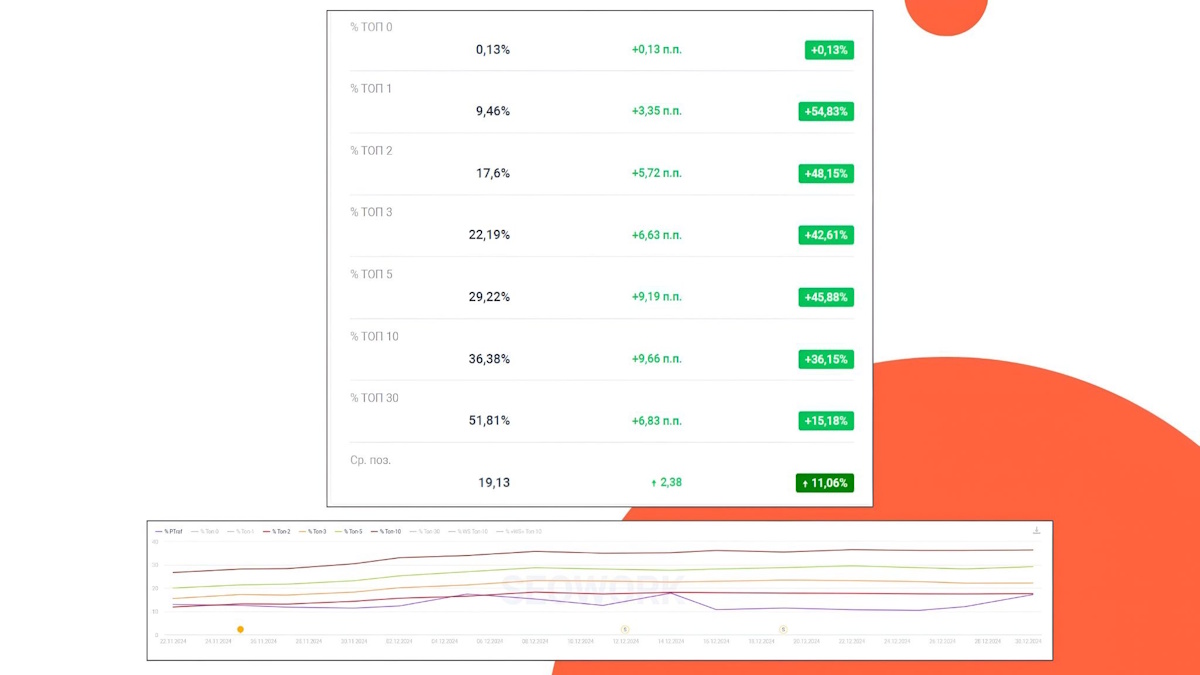
Рост позиций в Гугл
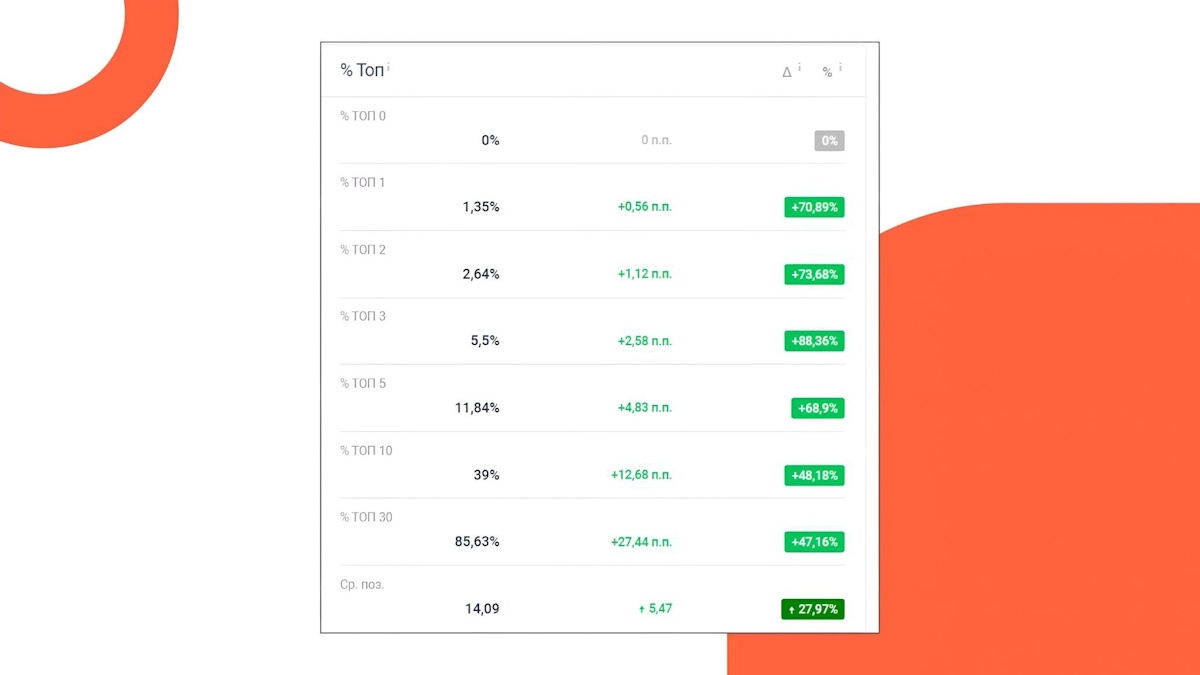
Чемодан 5
Товарные блоки советов «Похожие продукты» и «Приобретают совместно» не индексировались.
Опосля вывода блоков в SSR позиции выросли и в Yandex’е, и в Гугл.
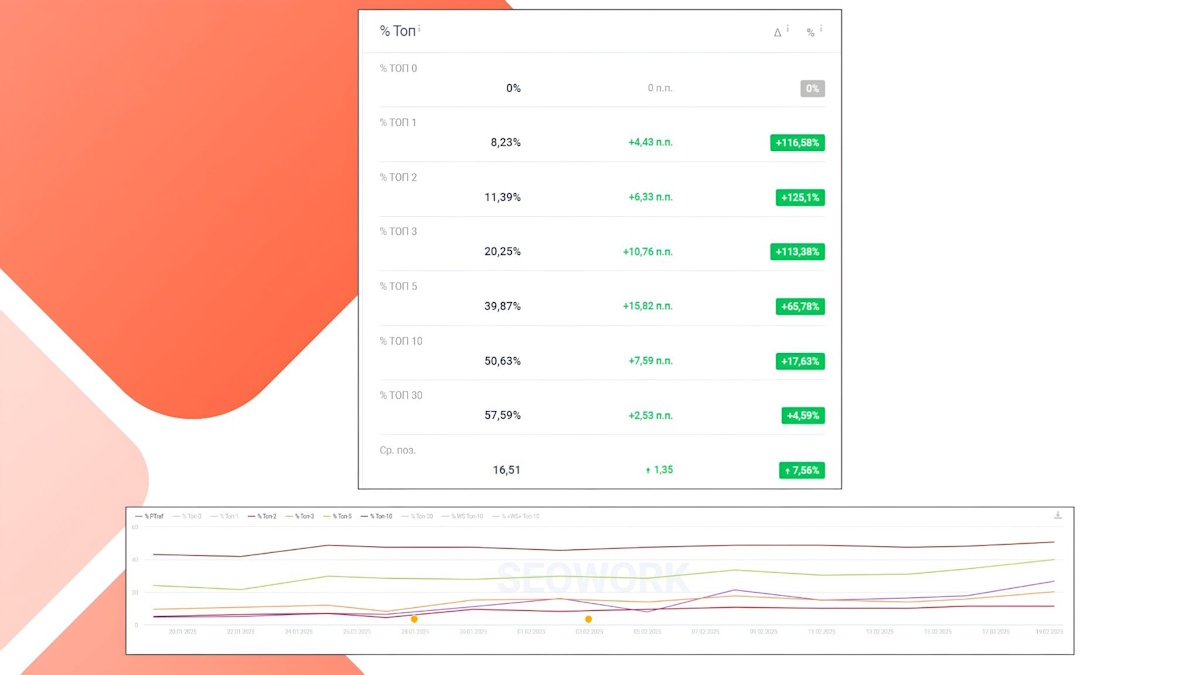
Рост позиций в Yandex’е
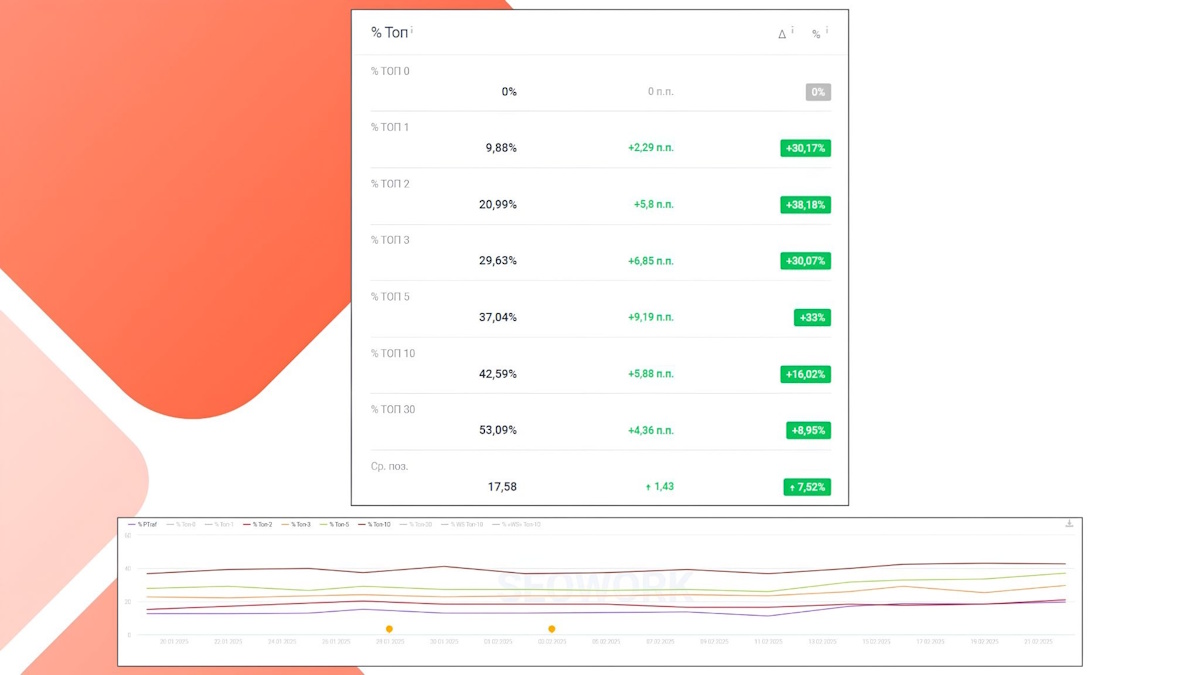
Рост позиций в Гугл
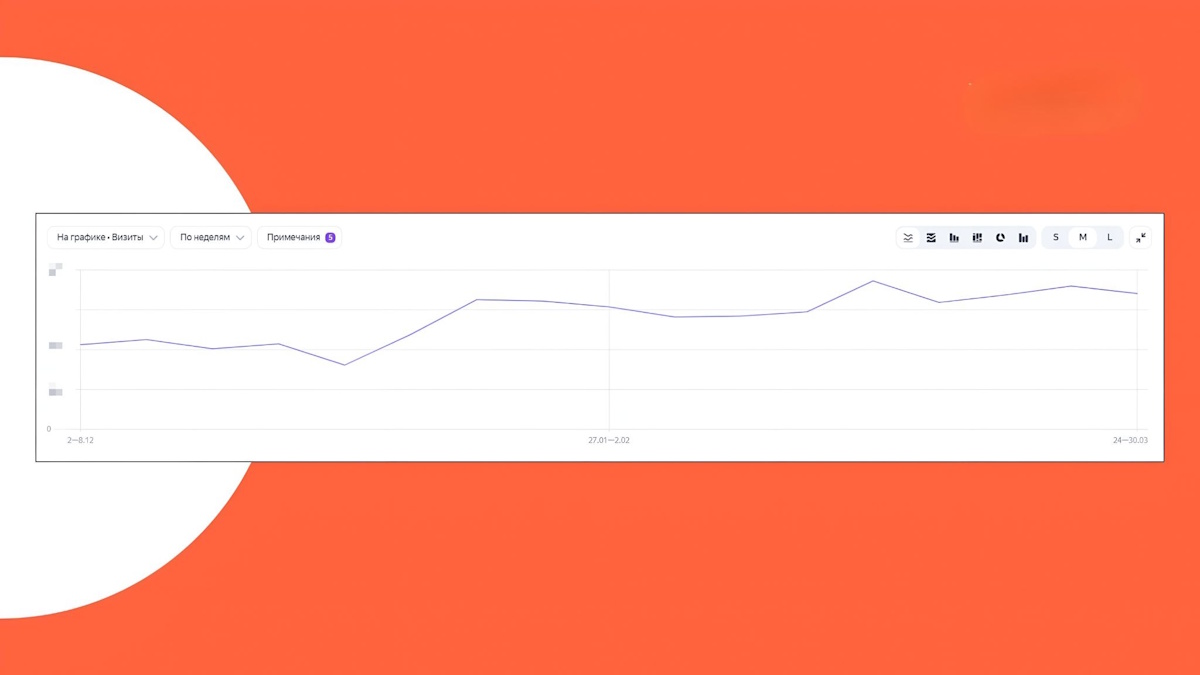
Рост трафика из Поиска
Чемодан 6
Меню не подгружалось в SSR.
Видимость в Yandex’е стала лучше опосля опции индексации меню.
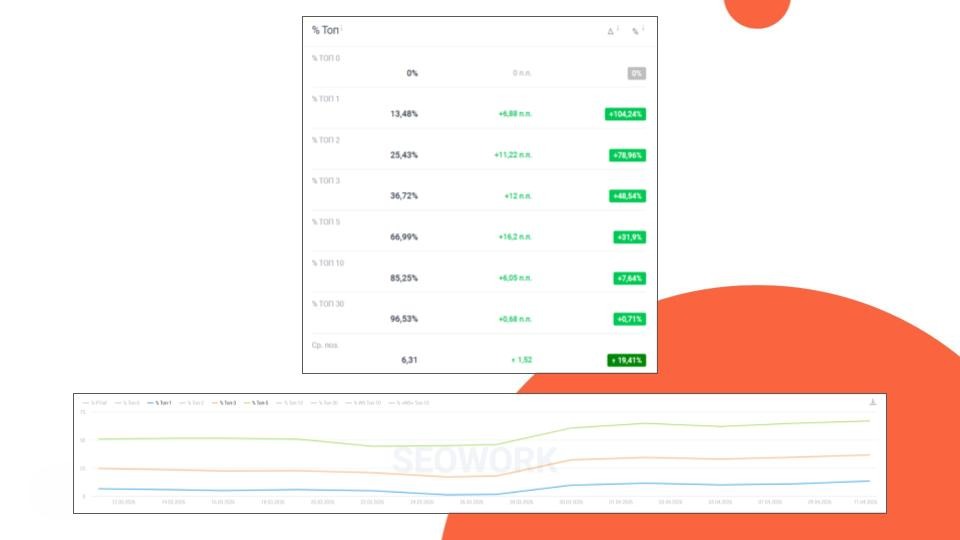
Рост позиций в Yandex’е
SSR в e-commerce: не формальность, а точка риска
SSR – это не «галочка» в чеклисте. Это ответственность за HTML, который получает поисковик.
Для e-commerce в Рф SSR должен быть:
-
полным (все главные элементы – в HTML);
-
семантически корректным (ссылки – через < a >);
-
единым для всех устройств;
-
незапятнанным от нерелевантного контента.
Если вы реализуете в РФ (Российская Федерация — государство в Восточной Европе и Северной Азии, наша Родина) – не ориентируйтесь лишь на Гугл. Yandex как и раньше просит «добросовестного» HTML. И если ваша SSR-верстка нарушает хотя бы одну из обрисованных выше заморочек, то вы теряете трафик, конверсии и… средства.

Оригинал статьи на SEOnews